Corona-Statistiken auf dem Prüfstand: Was uns Schweizer Medien servieren
In den Medienberichten zur Corona-Pandemie spielen Zahlen eine zentrale Rolle. Kaum ein Bericht, der sich nicht auf eine Statistik abstützt oder damit argumentiert. Nicht selten zeigt ein zweiter Blick elementare Mängel im Umgang mit dem Zahlenmaterial. Wir haben Beispiele von Corona-Statistiken in verschiedenen Medien unter die Lupe genommen.

«Ich studiere Statistik seit über 40 Jahren und verstehe sie immer noch nicht. Die Leichtigkeit, mit der Nicht-Statistiker sie meistern, ist erstaunlich.» Der ironische Kommentar des Biostatistikers Stephen Senn bringt die Problematik des medialen Umgangs mit statistischen Kennzahlen wunderbar auf den Punkt: Hochkomplexe statistische Zusammenhänge werden gerne auf knackige Schlagzeilen und einfach wirkende Empfehlungen verdichtet; Unsicherheiten bleiben unerwähnt oder werden aufgebauscht; unbewiesene Vermutungen verwandeln sich in gesicherte Kausalzusammenhänge.
Erstaunlich ist das nicht. Statistische Informationen verständlich und korrekt zu vermitteln, ist eine Kunst, die mathematisches Können, fachspezifisches Wissen und gestalterisches Geschick verlangt. Die Gefahr, über statistische Fallstricke zu stolpern, ist deshalb gross. Das gilt für unsinnige Vergleiche von Terror- mit Unfalltoten genauso wie für Berichte über den «Durchschnittsschweizer».
Sobald in Medienberichten statistische Kennzahlen ins Spiel kommen, ist Vorsicht geboten. Das zeigt auch die gegenwärtige Berichterstattung zu COVID-19, die besonders anfällig für statistische Stolpersteine ist, weil Infektions- und Todeszahlen sowie epidemiologische Modellierungen eine derart grosse Bedeutung in der öffentlichen Diskussion einnehmen. Viele Journalisten sind sich dessen bewusst. Die «Republik» veröffentlichte beispielsweise eine Erklärung, wie sie mit wissenschaftlichen Informationen rund um COVID-19 umgehen. In der NZZ erschien ein Artikel, der die bisweilen intransparenten Berechnungen und Modelle von Medien und Forschungseinrichtungen zum Schätzen der genesenen Patienten kritisierte. Und auch im Wissen-Teil des «Tages-Anzeigers» erschien ein Artikel über die Herausforderungen beim Lesen von Corona-Statistiken.
Darauf aufbauend möchte ich einige Punkte ausführen, auf die es zu achten gilt, wenn Medien Statistiken verwenden – illustriert anhand positiver und negativer Beispiele im Zusammenhang mit der aktuellen Corona-Berichterstattung. Beispiele, die weder für die Medienlandschaft als Ganzes, noch für die erwähnten Publikationen repräsentativ sind.
Es handelt sich also nicht um eine systematische Analyse der Qualität von Statistiken in Schweizer Medien. Das würde sowohl meine zeitlichen Ressourcen wie auch meine wissenschaftliche Kompetenz übersteigen, weshalb ich diese Aufgabe Experten wie jenen vom Forschungszentrum «Öffentlichkeit und Gesellschaft» der Universität Zürich mit ihrem Jahrbuch «Qualität der Medien» überlasse.
Die nachfolgenden Beispiele dienen lediglich als Illustration zu den Fragen, die ich aufwerfe. Diese Unterscheidung zwischen Anschauungsbeispielen einerseits und repräsentativen Aussagen andererseits ist dann auch bereits die erste wichtige Lektion, die es beim Umgang mit statistischen Informationen zu verinnerlichen gilt: Ein illustratives Beispiel ist keine repräsentative Untersuchung, eine Anekdote kein Beweis.
Tücken im Umgang mit Statistiken:
- wie viele Mikrogramm Feinstaub normalerweise in der Luft zirkulieren;
- über welchen Zeitraum eine erhöhte Konzentration gegeben sein muss, um zu schaden;
- welchen Schwankungen die Feinstaubbelastung normalerweise unterliegt;
- wie stark der Einfluss anderer Risikofaktoren auf das Sterberisiko durch COVID-19 ist.
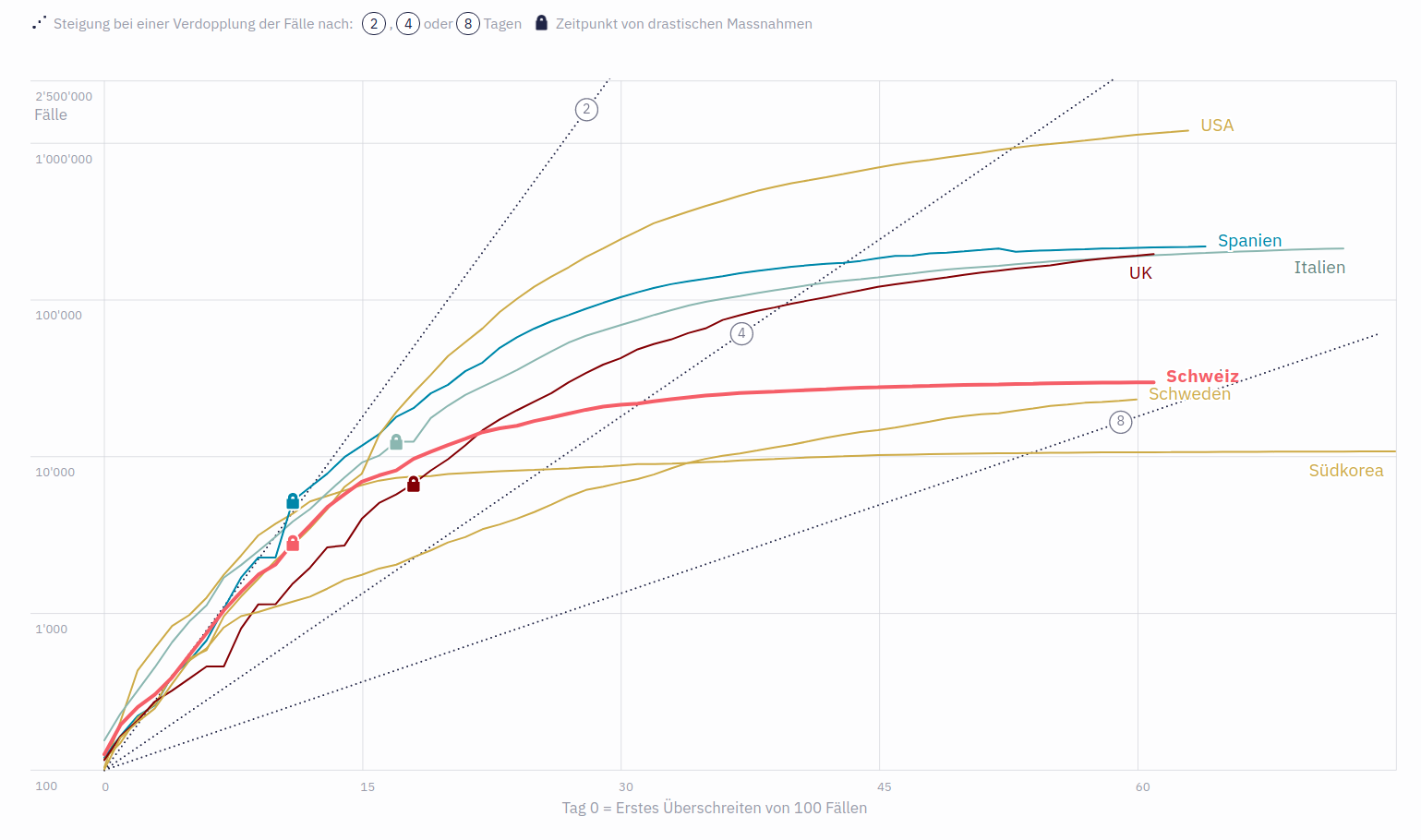 All jene, die mehr zu den Begebenheiten in den einzelnen Ländern erfahren möchten, erhalten zudem über eine aufklappbare Textbox weitere Informationen.
Abgerundet wird das Ganze mit dem expliziten Hinweis, dass die Daten auf der vertikalen Achse logarithmisch aufgetragen sind, und einer Erklärung, wie logarithmischen Skalen zu interpretieren sind. Solche «Leseanleitungen» sind essentiell für das Verständnis der Lesenden, die keine Erfahrung im Umgang mit solchen Darstellungen haben.
Doch auch bei dieser Grafik gibt es Verbesserungspotential. So sollte beispielsweise angeben werden, woher die verwendeten Daten stammen, sowie, dass es bei den Teststrategien der einzelnen Länder erhebliche Unterschiede geben kann, was sich auch auf die Fallzahlen auswirkt.
Als Negativbeispiel muss eine Grafik der NZZ herhalten, in der die Zahlen der täglichen Todesfälle in unterschiedlichen Ländern miteinander verglichen werden.
All jene, die mehr zu den Begebenheiten in den einzelnen Ländern erfahren möchten, erhalten zudem über eine aufklappbare Textbox weitere Informationen.
Abgerundet wird das Ganze mit dem expliziten Hinweis, dass die Daten auf der vertikalen Achse logarithmisch aufgetragen sind, und einer Erklärung, wie logarithmischen Skalen zu interpretieren sind. Solche «Leseanleitungen» sind essentiell für das Verständnis der Lesenden, die keine Erfahrung im Umgang mit solchen Darstellungen haben.
Doch auch bei dieser Grafik gibt es Verbesserungspotential. So sollte beispielsweise angeben werden, woher die verwendeten Daten stammen, sowie, dass es bei den Teststrategien der einzelnen Länder erhebliche Unterschiede geben kann, was sich auch auf die Fallzahlen auswirkt.
Als Negativbeispiel muss eine Grafik der NZZ herhalten, in der die Zahlen der täglichen Todesfälle in unterschiedlichen Ländern miteinander verglichen werden.
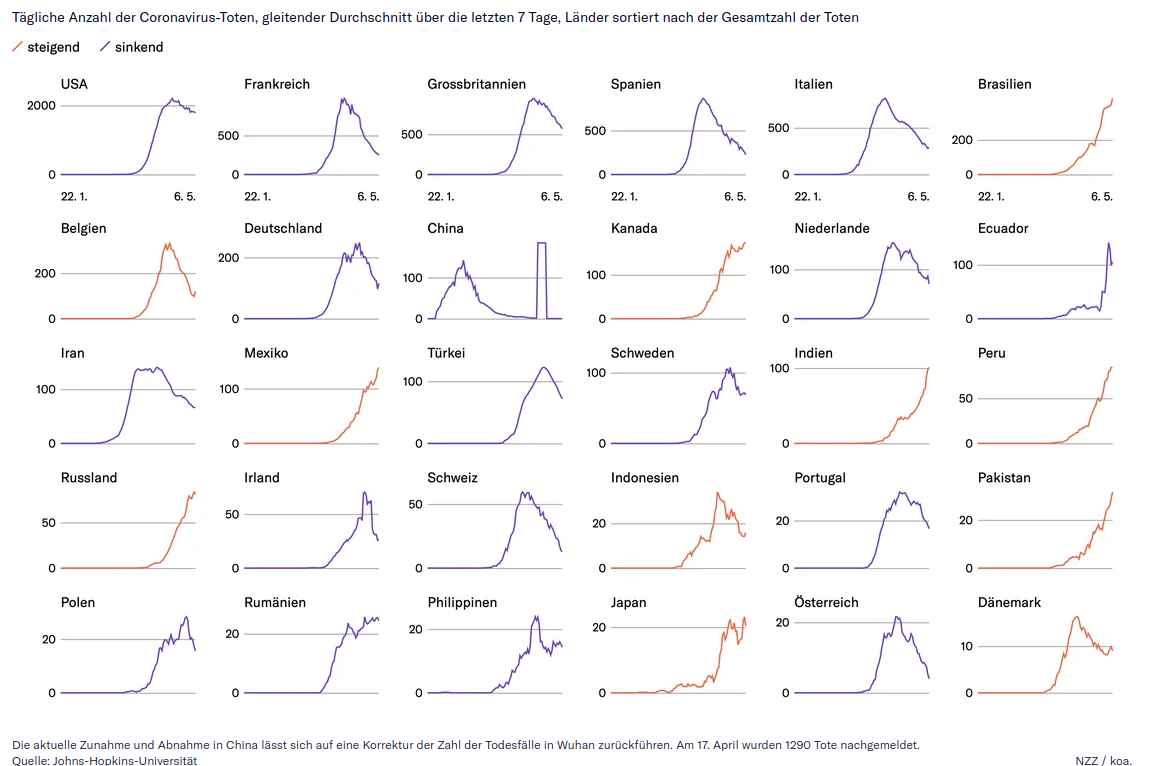 Die vertikale Achse scheint bei jedem Land unterschiedlich skaliert zu sein und es ist auch nicht angegeben, ob es sich um eine logarithmische oder lineare Skala handelt. Und da auf jeder einzelnen Grafik nur jeweils zwei Werte angegeben sind, lässt sich diese Information auch nicht ablesen. Ebenso wenig ist in der Legende ersichtlich, dass die horizontale Linie in den Grafiken den Durchschnittswert der vergangenen sieben Tage darstellen soll. All dies erschwert die Interpretation und Vergleichbarkeit enorm. Positiv zu erwähnen ist jedoch, dass der statistische Ausreisser bei den Todesfällen in China erklärt wird und die Datenquellen ausgewiesen sind.
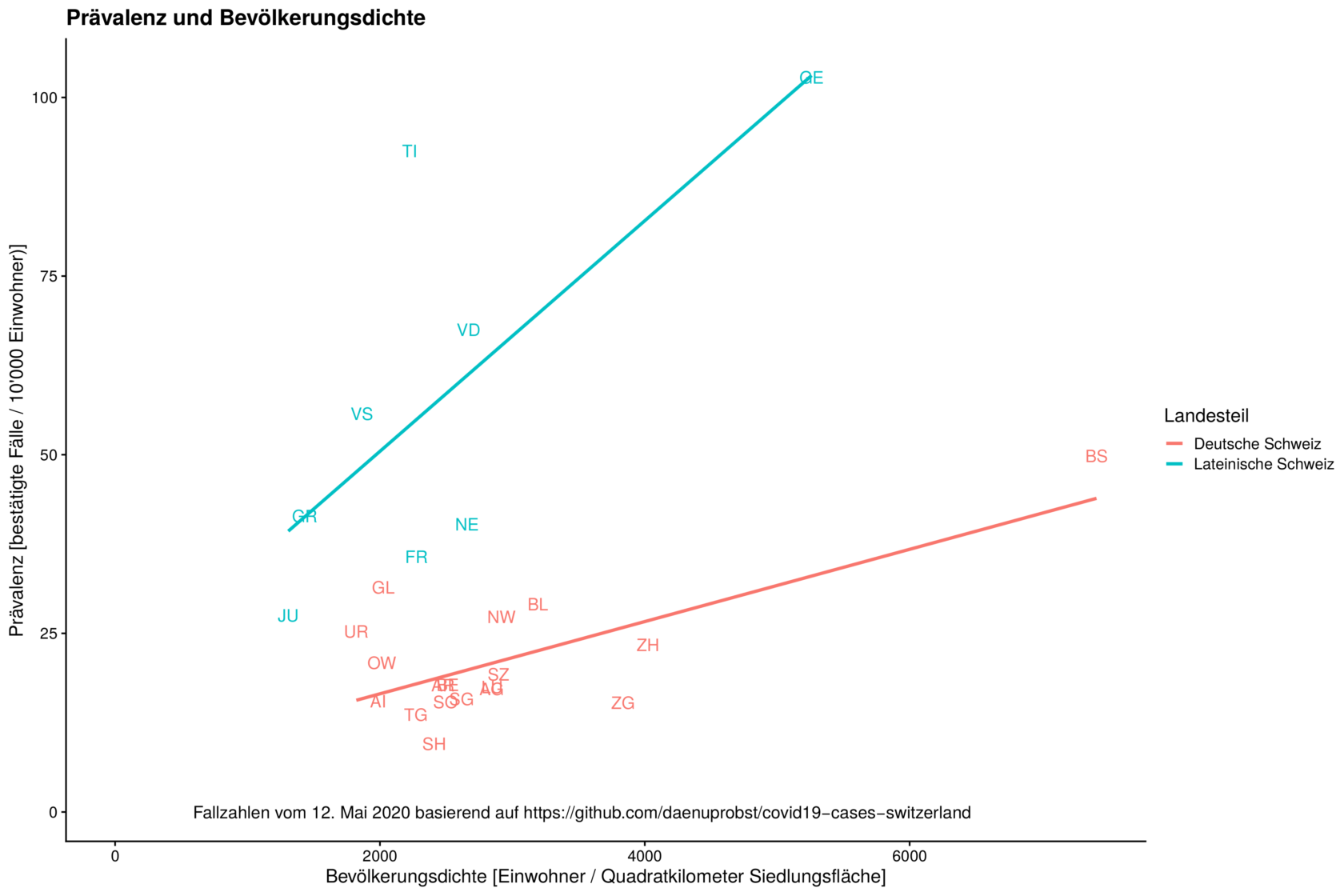
Die vertikale Achse scheint bei jedem Land unterschiedlich skaliert zu sein und es ist auch nicht angegeben, ob es sich um eine logarithmische oder lineare Skala handelt. Und da auf jeder einzelnen Grafik nur jeweils zwei Werte angegeben sind, lässt sich diese Information auch nicht ablesen. Ebenso wenig ist in der Legende ersichtlich, dass die horizontale Linie in den Grafiken den Durchschnittswert der vergangenen sieben Tage darstellen soll. All dies erschwert die Interpretation und Vergleichbarkeit enorm. Positiv zu erwähnen ist jedoch, dass der statistische Ausreisser bei den Todesfällen in China erklärt wird und die Datenquellen ausgewiesen sind. 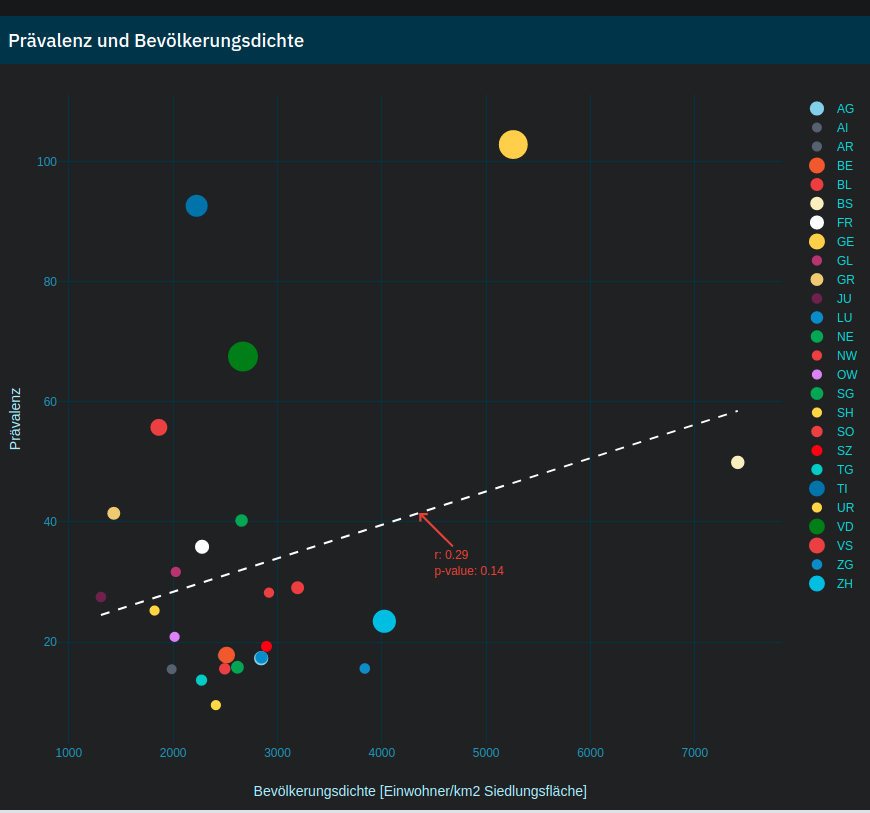 Der verwendete Test ist zwar nicht signifikant, doch weil das dafür verwendete statistische Mass nur für lineare Zusammenhänge geeignet ist, lässt sich daraus nicht schliessen, dass zwischen Bevölkerungsdichte und Infektionszahlen kein Zusammenhang besteht. Unterscheidet man jedoch zwischen Kantonen der lateinischen und der deutschen Schweiz, dann erscheint ein leichter linearer Zusammenhang durchaus plausibel.
Der verwendete Test ist zwar nicht signifikant, doch weil das dafür verwendete statistische Mass nur für lineare Zusammenhänge geeignet ist, lässt sich daraus nicht schliessen, dass zwischen Bevölkerungsdichte und Infektionszahlen kein Zusammenhang besteht. Unterscheidet man jedoch zwischen Kantonen der lateinischen und der deutschen Schweiz, dann erscheint ein leichter linearer Zusammenhang durchaus plausibel.
 Ein anderes Beispiel ist die Studie zur Virenbelastung bei Kindern, die eine Gruppe um den deutschen Virologen Christian Dorsten durchgeführt hat und die auch hierzulande für Diskussionen gesorgt hat. Die Studie wurde erst – auch von den Autoren selber – als Beleg dafür gewertet, dass kein signifikanter Unterschied zwischen der viralen Belastung von Kindern und Erwachsenen besteht. Rein technisch war dieser Schluss basierend auf verwendeten Tests korrekt. Doch wer sich die einzelnen Effektgrössen samt den dazugehörigen Unsicherheitsbereichen anschaute, der erkannte, dass die Virenbelastung bei Kindern im Durchschnitt tiefer war als bei Erwachsenen.
Auf Twitter hat ein Statistiker explizit darauf hingewiesen, doch die damit zusammenhängenden Nuancen gingen in der medialen Berichterstattung komplett verloren. Der «Blick» titelte unter Berufung auf die Studie «Kinder vermutlich genauso ansteckend wie Erwachsene». Der «Tages-Anzeiger» schrieb «Kinder könnten genauso ansteckend sein wie Erwachsene» und in der NZZ hiess es fälschlicherweise, «die Zahl der Viren, die sich in den Atemwegen nachweisen liessen, unterscheide sich bei verschiedenen Altersgruppen nicht». Immerhin wurde darauf verwiesen, dass es sich um eine noch ungeprüfte Vorabveröffentlichung handelte.
In der Zwischenzeit hat eine Neuanalyse durch den Biostatistiker Leonhard Held von der Universität Zürich ergeben, dass bei Verwendung anderer Auswertungsmethoden ein moderater Zusammenhang zwischen dem Alter und der Virenbelastung festgestellt werden kann. Bis zum jetzigen Zeitpunkt (15. Mai, 22h00), haben aber weder «Tages-Anzeiger», noch «Blick» noch NZZ darüber berichtet – nur die CH-Media-Tageszeitungen haben die Analyse aufgegriffen.
Ein anderes Beispiel ist die Studie zur Virenbelastung bei Kindern, die eine Gruppe um den deutschen Virologen Christian Dorsten durchgeführt hat und die auch hierzulande für Diskussionen gesorgt hat. Die Studie wurde erst – auch von den Autoren selber – als Beleg dafür gewertet, dass kein signifikanter Unterschied zwischen der viralen Belastung von Kindern und Erwachsenen besteht. Rein technisch war dieser Schluss basierend auf verwendeten Tests korrekt. Doch wer sich die einzelnen Effektgrössen samt den dazugehörigen Unsicherheitsbereichen anschaute, der erkannte, dass die Virenbelastung bei Kindern im Durchschnitt tiefer war als bei Erwachsenen.
Auf Twitter hat ein Statistiker explizit darauf hingewiesen, doch die damit zusammenhängenden Nuancen gingen in der medialen Berichterstattung komplett verloren. Der «Blick» titelte unter Berufung auf die Studie «Kinder vermutlich genauso ansteckend wie Erwachsene». Der «Tages-Anzeiger» schrieb «Kinder könnten genauso ansteckend sein wie Erwachsene» und in der NZZ hiess es fälschlicherweise, «die Zahl der Viren, die sich in den Atemwegen nachweisen liessen, unterscheide sich bei verschiedenen Altersgruppen nicht». Immerhin wurde darauf verwiesen, dass es sich um eine noch ungeprüfte Vorabveröffentlichung handelte.
In der Zwischenzeit hat eine Neuanalyse durch den Biostatistiker Leonhard Held von der Universität Zürich ergeben, dass bei Verwendung anderer Auswertungsmethoden ein moderater Zusammenhang zwischen dem Alter und der Virenbelastung festgestellt werden kann. Bis zum jetzigen Zeitpunkt (15. Mai, 22h00), haben aber weder «Tages-Anzeiger», noch «Blick» noch NZZ darüber berichtet – nur die CH-Media-Tageszeitungen haben die Analyse aufgegriffen. - Zufällige Schwankungen: Besonders bei kleinen Stichproben ist Vorsicht bei der Interpretation geboten, da die berechneten Kennzahlen stärker um den tatsächlichen Wert schwanken als bei grossen Stichproben. Aus diesem Grund sollte nie über eine einzelne Studie berichtet werden, ohne diese in den Kontext mit andern Untersuchungen des gleichen Themas zu setzen. Noch besser wäre es, sich auf systematische Zusammenfassungen der wissenschaftlichen Literatur zu diesem Thema zu stützen.
- Systematische Verzerrungen: In der Schweiz wurden hauptsächlich Risikopatienten und Menschen mit einem schweren Krankheitsverlauf auf SARS-CoV-2 getestet. Die getesteten Personen stellen also keine zufällige Auswahl der Gesamtbevölkerung dar. Repräsentative Untersuchungen wie jene der Universität Genf versuchen, diese Verzerrungen zu beheben.
- Wissenschaftliche Unklarheiten: SARS-CoV-2 wird seit weniger als 6 Monaten wissenschaftlich untersucht. Die wissenschaftliche Forschung bewegt sich deshalb in vielerlei Hinsicht auf unbekanntem Gebiet. Die involvierten Wissenschaftler müssen laufend dazulernen und alte Hypothesen mit neuen Daten abgleichen. Demgegenüber wird etwa der Zusammenhang von CO2 auf die globalen Durchschnittstemperaturen schon seit Jahrzehnten untersucht – entsprechend besser abgestützt sind die entsprechenden wissenschaftlichen Ergebnisse.
- Menschliche Fehler: Auch Wissenschaftler sind nur Menschen und können Fehler begehen. Aus diesem Grund ist es entscheidend, dass wissenschaftliche Publikationen kritisch von anderen Fachleuten begutachtet werden («Peer Review»). Das ist noch keine Garantie, dass alle Fehler erkannt wurden, aber Veröffentlichungen, die noch nicht von anderen Fachleuten begutachtet wurden, sollten sehr vorsichtig ausgelegt werden. Im Zusammenhang mit COVID-19 sollten Medienschaffende das ganz besonders berücksichtigen. Aufgrund des Zeitdrucks werden viele neue Ergebnisse als sogenannte «Pre-Prints» veröffentlicht und damit meist ohne vorangehende Überprüfung durch andere Forschende. Mit allergrösster Vorsicht zu geniessen sind Publikationen, bei denen die Forschenden sich zuerst mittels einer Medienmitteilungen an die Öffentlichkeit wenden, also bevor andere Wissenschaftler überhaupt die Möglichkeit hatten, die Ergebnisse zu überprüfen. Aufgrund des gesteigerten Zeitdrucks gehört dieses «science by press release» oder «science by press conference» bei der Forschung zu COVID-19 fast schon zur Normalität. Ein Beispiel dafür ist die Pressemitteilung der Universität Genf zu den ersten Ergebnissen ihrer Antikörperstudie. Die Medienmitteilung mit den Resultaten wurde bereits am 22. April veröffentlicht, der Pre-Print mit den detaillierten Angaben zur Methodik und zur Erhebung der Daten erst am 6. Mai. Immerhin teilte die Studienleiterin Silvia Stringhini auf Twitter das Studienprotokoll noch am Tag der Medienmitteilung und wies durchaus selbstkritisch auf die Schwierigkeit hin, den enormen politischen Druck nach zügigen Resultaten in Einklang zu bringen mit solider und seriöser Überprüfung der Daten.
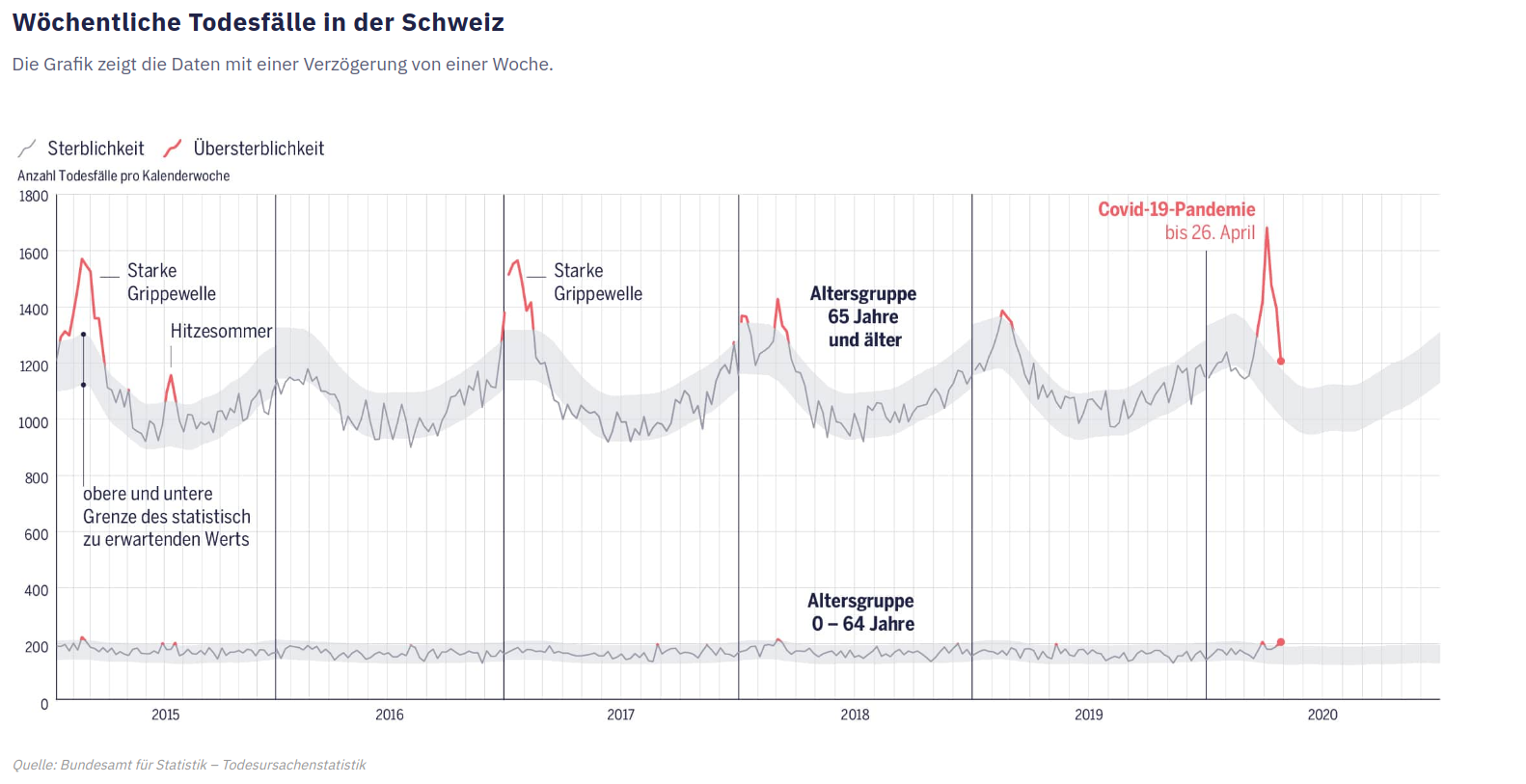 Es bleibt zwar unklar, wie dieser Wert berechnet wurde, basierend auf welchen Annahmen die Grenzen gezogen wurden und um welche Art von Unsicherheitsbereich es sich handelt, beziehungsweise was als «normal» bzw. «zu erwartend» zu interpretieren ist. Diese Informationen erhält nur, wer sich auf der Website des Bundesamts für Statistik schlau macht. Doch die Lesenden erhalten auf einen Blick die entscheidende Kernaussage vermittelt, dass bei den wöchentlichen Todeszahlen mit gewissen statistischen Schwankungen zu rechnen ist und dass diese Schwankungen sich mit einer gewissen Wahrscheinlichkeit im angegebenen Rahmen bewegen.
Es bleibt zwar unklar, wie dieser Wert berechnet wurde, basierend auf welchen Annahmen die Grenzen gezogen wurden und um welche Art von Unsicherheitsbereich es sich handelt, beziehungsweise was als «normal» bzw. «zu erwartend» zu interpretieren ist. Diese Informationen erhält nur, wer sich auf der Website des Bundesamts für Statistik schlau macht. Doch die Lesenden erhalten auf einen Blick die entscheidende Kernaussage vermittelt, dass bei den wöchentlichen Todeszahlen mit gewissen statistischen Schwankungen zu rechnen ist und dass diese Schwankungen sich mit einer gewissen Wahrscheinlichkeit im angegebenen Rahmen bewegen. Statistiken sollten Erkenntnisse schaffen, nicht Meinungen bestätigen. Das unterscheidet einen seriösen Umgang mit statistischen Kennzahlen von einem unseriösen. Wenn der Schluss am Anfang der Geschichte steht und die Statistik lediglich dazu dienen soll, den eigenen Argumenten mehr Gewicht zu geben, dann kann man gleich auf sie verzichten. Dasselbe gilt im Übrigen für Expertenmeinungen: Wer nur Experten befragt, die den eigenen Schluss stützen, macht es sich zu einfach.
Statistiken so aufzubereiten, dass sie aussagekräftig, verständlich und dennoch korrekt sind, ist eine Kunst. Und weil ich weiss, wie schwierig es ist, diese hohen Anforderungen zu erfüllen, ist es mir wichtig zu betonen: Die oben besprochenen Beispiele allein lassen keine Aussage über die Expertise ihrer Urheber zu. Viele der diskutierten Fehler kenne ich aus eigener Erfahrung und einige davon begehe auch ich, wenn ich unter Zeitdruck stehe. Insofern kann ich verstehen, dass nicht alles, was aus der Perspektive eines statistischen Erbsenzählers wünschenswert ist, auch umsetzbar ist – insbesondere aufgrund des enormen Zeitdrucks, dem Journalistinnen und Journalisten in der Regel ausgesetzt sind.
Die perfekte Statistik gibt es nicht. Was in einer Situation nützlich und informativ ist, kann im nächsten Fall komplett in die Irre führen.
Dennoch erachte ich es als eine entscheidende redaktionelle Aufgabe, komplexe statistische und wissenschaftliche Informationen sauber und verständlich aufzubereiten. Denn einige Menschen schliessen aus der Existenz bestimmter Unsicherheiten fälschlicherweise auf die Abwesenheit jedweder Gewissheit – und nehmen dies als Ausrede, um ihre eigene Meinung gleichberechtigt neben eine saubere Analyse der vorhandenen, wenn auch mit Unsicherheiten behafteten, Informationen zu stellen. Umso wichtiger ist es, dass Medienhäuser ihren Angestellten genügend Zeit und Ressourcen zur Verfügung stellen, um dem entgegenhalten zu können.
Und schliesslich ist es wichtig zu erwähnen, dass es «die» perfekte Statistik nicht gibt. Was in einer Situation nützlich und informativ ist, kann im nächsten Fall komplett in die Irre führen. Das ist kein Aufruf zur Beliebigkeit, sondern zur Berücksichtigung des Kontexts, in dem eine Statistik verwendet wird. Statistiken sind wie Worte: Richtig und umsichtig eingesetzt können sie den Horizont erweitern. Wer sie fahrlässig verwendet, führt in die Irre, statt Klarheit zu schaffen.
Heiner Motschi 16. Mai 2020, 06:41
Sehr erhellend von A bis Z, danke. – Diese Einsichten muss man auch auf die Klimadebatte übertragen, wenn denn das überhaupt noch eine Debatte ist und nicht ein simples Niederschreien.
Theo Schmidt 18. Mai 2020, 15:17
Bei der Klimaerwärmung geht es mehr um Messungen als um Statistik. Ausserdem geht es dort um ein sehr träges System, während die Coronakrise sehr rasch stattfindet und sich wegen der vielen teils kaum bekannten Faktoren mathematisch nur sehr grob modellieren lässt.